
2026年3月17-21日 · 圣何塞
NVIDIA GTC 2026
深度分析报告
从 Blackw ell Ultra 到 Vera Rubin,再到 Feynman 预览——全面解析黄仁勋主题演讲中的硬件革命、软件生态与战略蓝图,探索物理 AI 与机器人时代的算力新纪元。
开始探索
向下滚动
从 Blackw ell Ultra 到 Vera Rubin,再到 Feynman 预览——全面解析黄仁勋主题演讲中的硬件革命、软件生态与战略蓝图,探索物理 AI 与机器人时代的算力新纪元。
开始探索GTC(GPU Technology Conference)是全球最重要的 AI 与加速计算盛会,2026 年规模再创新高,汇聚了超过 25 万名注册参会者(线上线下),发布了从数据中心到机器人领域的全方位产品矩阵。

黄仁勋在 SAP 中心发表长达两小时的主题演讲,公布 Blackwell Ultra、Vera Rubin 平台、GR00T N1 机器人基础模型、Dynamo 1.0 推理框架等重磅产品,全面定义 AI 工厂时代的技术路线图。

GTC 2026 的核心议题从生成式 AI 扩展至物理世界 AI:机器人、数字孪生、自动驾驶、工业仿真。黄仁勋提出"AI 工厂"概念,强调推理计算将在未来占据主导地位。
Blackwell Ultra(B300)是 NVIDIA 数据中心 GPU 的最新旗舰,基于台积电 N4P 增强制程,在显存容量、推理性能、AI 工厂效率上实现了全面跨越式提升,预计 2026 年下半年大规模出货。

72 颗 B300 GPU + 36 颗 Grace CPU,通过 NVLink 构成全互联域,总显存高达 20.7TB,130 TB/s 全对全互联带宽,专为超大规模 AI 推理集群设计。
16 颗 B300 GPU 通过 NVLink 互联,形成高带宽并行计算集群,适合企业级 AI 训练与推理任务,提供标准服务器集成方案。

专业工作站级别 GPU,面向 AI 开发、数据科学、实时光线追踪等高要求工作负载,提供数据中心级的 Blackwell 架构能力下放至桌面端。
基于台积电 N4P 增强制程,Blackwell Ultra GPU 配备第 5 代 Tensor Core(支持 FP4/NVFP4),2 倍注意力层加速,相比 B200 实现 1.5 倍训练性能和 1.5 倍推理性能提升,显存从 192GB 升级至 288GB HBM3e(6 堆栈 12-Hi)。
| 产品规格 | B200 (对比基线) | Blackwell Ultra (B300) | 提升幅度 |
|---|---|---|---|
| 制程工艺 | TSMC N4P | TSMC N4P (增强) | — |
| 晶体管数量 | ~208B | ~208B+ | 密度优化 |
| CUDA 核心 | 14,080 | 20,480 | +45.5% |
| 单卡显存 | 192 GB HBM3e | 288 GB HBM3e (12-Hi) | +50% |
| 显存带宽 | ~8 TB/s | ~8 TB/s | 持平 |
| FP4 训练性能 | ~10 PFLOPS | 15 PFLOPS | +1.5× |
| FP4 推理性能 | ~33 PFLOPS | 50 PFLOPS | +51.5% |
| INT8 性能 | ~220 TOPS | ~330 TOPS | +50% |
| 网络互联 | ConnectX-7 (400Gb/s) | ConnectX-8 (800Gb/s) | 2× |
| GPU TDP | ~1000W | ~1400W | 液冷需求↑ |
| NVLink 带宽 | ~1.8 TB/s | ~1.8 TB/s (Gen5) | — |
NVIDIA 公布了从 Blackwell Ultra 到 Vera Rubin(2027)再到 Feynman(2028)的完整加速计算路线图,每代产品均实现性能数量级的跃升。

Vera Rubin 平台包含 Rubin GPU(8 堆栈 HBM4)、Vera CPU(72 核 Arm v9.2-A)以及 NVL144 机架系统。Rubin GPU 采用全新架构设计,相比 Blackwell Ultra 实现 3.3 倍 FP4 性能提升,预计 2027 年下半年出货。

Vera CPU 基于 Arm v9.2-A 架构,72 核心,支持双线程,提供 1.8 TB/s LPDDR6X 内存带宽。与 Rubin GPU 共同构成 NVL144 机架系统,每瓦性能相比 Grace-Blackwell 提升 10 倍。

NVIDIA 首个同时集成自研 GPU 与 CPU 的平台。Rubin GPU 采用全新架构设计,8 堆栈 HBM4 显存;Vera CPU 为 72 核 Arm v9.2-A 架构,支持双线程,LPDDR6X 内存带宽高达 1.8 TB/s。NVL144 机架配置 144 颗 GPU + 72 颗 CPU,FP4 性能达 50 ExaFLOPS(相比 GB300 提升 3.3 倍)。
Vera CPU 是 NVIDIA 第二代自研数据中心 CPU,采用 Arm v9.2-A 架构,72 核心,支持双线程,提供 1.8 TB/s 的 LPDDR6X 内存带宽。与 Rubin GPU 共同构成"超级芯片"平台,每瓦性能相比 Grace-Blackwell 提升 10 倍,专为代理式 AI(Agentic AI)和大规模推理设计。
NVIDIA 宣布了完整的机器人技术栈:从硬件(Jetson Thor)到基础模型(GR00T N1)再到合成数据生成(Isaac GR00T Blueprint),以 Cosmos 世界基础模型为核心,正在构建机器人时代的 Android 生态。

基于 Blackwell 架构的旗舰级边缘 AI 计算平台,专为类人机器人设计,提供 800 TOPS INT8 算力,支持实时感知、决策与运动控制。

NVIDIA 发布的通用人形机器人 AI 大脑(Vision-Language-Action 模型),支持开放定制与微调,在 RoboArena 评测中排名第一。N2 版本预计 2026 年底发布。

基于 Omniverse Cosmos 世界基础模型,用于合成运动数据生成。解决机器人训练中数据稀缺的瓶颈问题,通过物理仿真生成大规模多样化运动数据。
GTC 2026 最大的软件发布是 NVIDIA Dynamo 1.0——开源推理框架,被称为"AI 工厂的操作系统",将推理效率提升至全新高度。同时 Omniverse、Cosmos、RTX 神经渲染等平台也迎来重大更新。

Dynamo 是专为 AI 工厂设计的高吞吐、低延迟分布式推理服务框架,定位为"AI 工厂的操作系统"。核心功能包括:智能推理路由、分离式解码(Disaggregated Decode)、基于 NIXL 的 KV 缓存卸载。与 vLLM、TensorRT-LLM、SGLang、LangChain 等主流开源框架原生集成。
NVIDIA 量子-经典混合计算平台,连接量子处理器(QPU)与经典 GPU 计算。与 IonQ 合作,实现量子计算与 Blackwell Ultra GPU 的无缝协作,面向药物研发、量子化学模拟、金融优化等前沿应用场景。
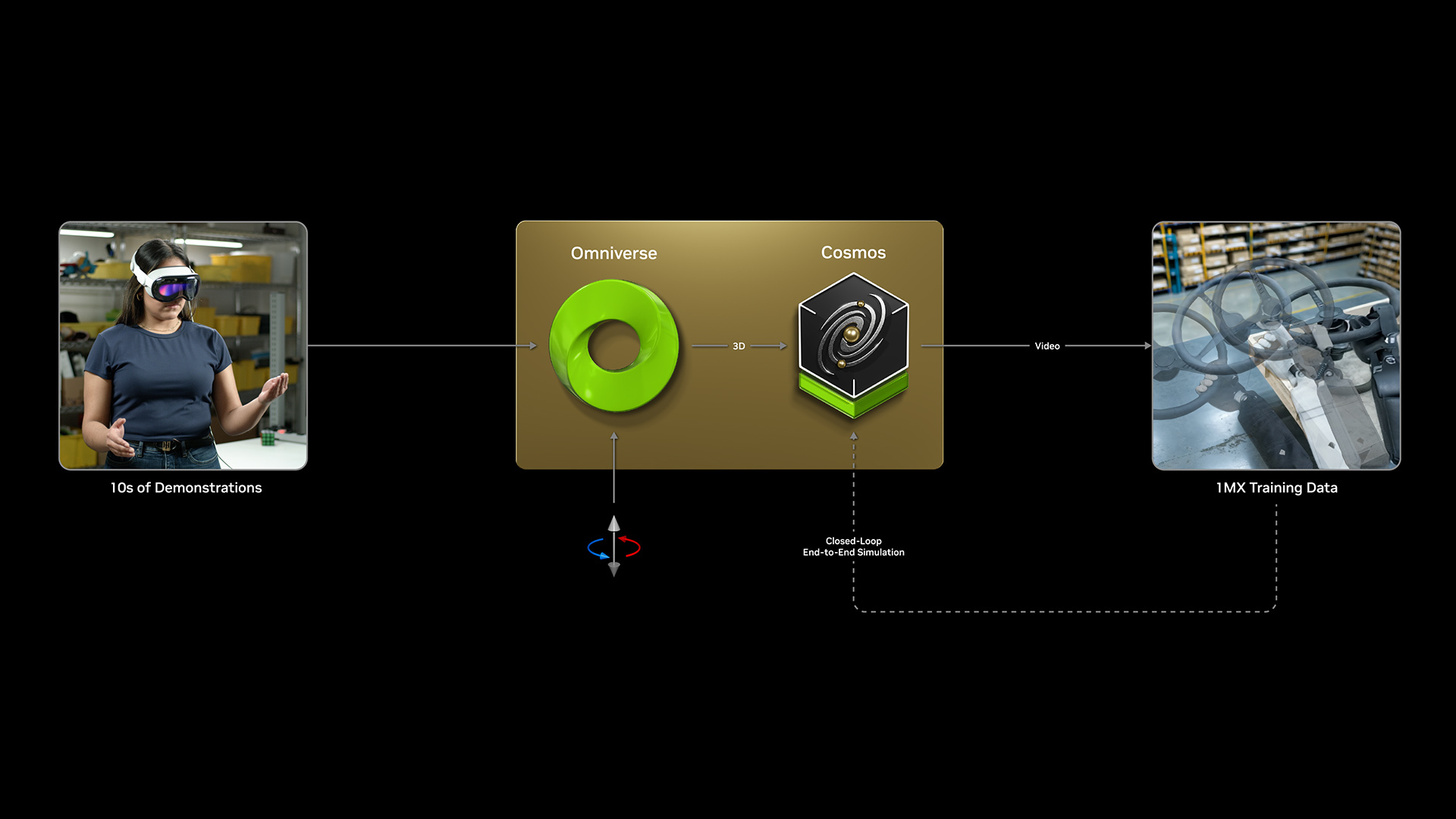
Cosmos 世界基础模型可生成物理感知视频,用于训练机器人的视觉导航与操作技能。Cosmos 3 版本进一步提升了物理真实性,支持更高分辨率的场景生成。与 Isaac GR00T Blueprint 结合,实现合成数据的规模化生产。

DLSS 4 引入多帧生成(Multi Frame Generation)技术,可在渲染帧之间智能生成额外画面,实现质与量的双重提升。神经纹理压缩技术大幅降低显存占用,RTX Neural Faces 实现实时数字人类渲染,达到照片级真实感。
CUDA 12.8 全面支持 Blackwell 架构,新增 NVFP4(NVFP4)低精度数据格式支持,CUTLASS 内核库针对大语言模型优化。提供完整的 Blackwell 优化算子库与工具链,MLPerf 推理首秀创下多项新纪录。

相比 vLLM,NVIDIA Dynamo 在 H100 上运行 DeepSeek R1 性能提升 30 倍,在 GB300 NVL72 上进一步提升 2.5 倍,在 Blackwell Ultra 上实现 MoE 吞吐 50 倍提升。这得益于智能推理路由、分离式解码和 KV 缓存卸载三大核心技术的协同优化。
以下数据综合自 NVIDIA 官方发布材料、MLPerf 基准测试结果及云厂商实例性能文档。
| 产品 | 制程 | FP4 训练 | FP4 推理 | 显存 | 网络 | 出货时间 |
|---|---|---|---|---|---|---|
| H100 SXM | TSMC 4N | ~4 PFLOPS* | ~4 PFLOPS* | 80 GB HBM3 | CX-7 (400Gb/s) | 已上市 |
| B200 | TSMC N4P | ~10 PFLOPS | ~33 PFLOPS | 192 GB HBM3e | CX-7 (400Gb/s) | 已上市 |
| Blackwell Ultra (B300) | TSMC N4P+ | 15 PFLOPS | 50 PFLOPS | 288 GB HBM3e | CX-8 (800Gb/s) | 2026 H2 |
| Vera Rubin | TSMC N3/N4 | 50 PFLOPS | ~200 PFLOPS | HBM4 | CX-9 (1.6Tbps) | 2027 H2 |
| Rubin Ultra | TSMC N3/N4 | 100 PFLOPS | ~400 PFLOPS | 1 TB HBM4e | CX-9 (1.6Tbps) | 2027 H2 |
| Feynman | TSMC A16 | >10× vs 当前 | >10× vs 当前 | 定制 HBM4E/5 | CX-10 (3.2Tb/s) | 2028 |
GTC 2026 不只是产品发布会,更是 NVIDIA 战略转型的宣言——从 GPU 芯片公司演变为 AI 全栈平台生态。
从生成式 AI(文本/图像/视频)迈向物理世界 AI。数字孪生平台(Omniverse)连接虚拟与现实,Cosmos 世界基础模型理解物理规律,Isaac 平台赋予机器人运动智能。NVIDIA 认为下一个万亿美元市场在于机器人、自动驾驶和工业数字孪生。
Dynamo 1.0 的定位从"推理框架"升级为"AI 工厂操作系统",类似 Linux 在数据中心中的地位——向下管理 GPU 集群、向上为 AI 应用提供标准化接口。通过开源策略与 vLLM、SGLang 等框架竞争,同时建立软件定义网络的护城河。
通过 GR00T N1、Jetson Thor、Isaac 平台的组合拳,NVIDIA 正在复制 Android 的开放生态策略——硬件抽象层(Thor)+ 基础模型(GR00T)+ 开发框架(Isaac + Hugging Face LeRobot)。目标是将自己定位为机器人时代的"操作系统"供应商。
面向未来 5-10 年的计算范式,NVIDIA 通过 AI-Q Blueprint 提前布局量子-经典混合计算。与 IonQ 的合作将量子处理单元(QPU)与 Blackwell GPU 无缝连接,在药物研发、量子化学、金融组合优化等领域寻找"量子优势"应用场景。

黄仁勋传达的最重要信息是"推理计算将超越训练计算"。Dynamo 的推出正是对这一趋势的战略回应——优化推理成本比提升训练性能更能直接转化为客户价值。NVIDIA 正在从芯片供应商转型为 AI 全栈平台生态,涵盖硬件(GPU/CPU)、软件(Dynamo/CUDA)、数据(Cosmos)和行业应用(机器人/自动驾驶/药物研发)。
NVIDIA GTC 2026 生态伙伴阵容空前强大,覆盖全球顶级云厂商、OEM/ODM 系统集成商以及十余个垂直行业应用领域。
NVIDIA 与 Arc Institute 等机构合作,利用量子-经典混合计算加速蛋白质折叠预测、药物分子设计和基因编辑研究。Blackwell Ultra 的超大显存(288GB)可完整加载超大模型进行药物筛选。
基于 Omniverse 的 Earth-2 数字孪生平台,利用 Cosmos 生成物理感知天气模拟数据,大幅提升气候模型的预测精度与分辨率。HBM4 的大带宽对科学计算尤为关键。
DRIVE Thor 平台集成 Blackwell 架构,为 L4/L5 自动驾驶提供 2000+ TOPS 算力,支持车载大模型实时推理。黄仁勋称之为"汽车的中央计算大脑"。

黄仁勋在 GTC 2026 主题演讲中发布 NeMoClaw——基于 Blackwell Ultra 的仿真框架,用于机器人运动策略训练。
Vera Rubin NVL144 机架系统支持大规模集群部署,每个机架包含 144 颗 Rubin GPU + 72 颗 Vera CPU,FP4 性能达 50 ExaFLOPS,专为超大规模 AI 推理设计。