一、总结
CUDA(Compute Unified Device Architecture,统一计算设备架构)是NVIDIA打造的GPU并行计算平台,它将GPU从图形渲染专用硬件转变为通用高性能计算平台。CUDA的核心价值在于让开发者能够像编写C/C++一样在GPU上编程,无需掌握复杂的图形API,从而实现高效的GPU并行处理。
🔑关键发现
- 简单运算(矩阵加法):CPU反而更快,因为GPU受数据传输瓶颈限制
- 复杂运算(矩阵乘法):GPU展现5-65倍加速,计算密集型任务才是GPU的主战场
- 矩阵规模越大:GPU优势越明显(1024: 5.4x → 4096: 64.6x)
- 优化策略:从朴素实现到cuBLAS库,性能可提升15倍以上
二、详细介绍
🎯CUDA是什么?
CUDA不只是一个简单的库,而是一个完整的生态系统:
| 组成部分 | 说明 | 举例 |
|---|---|---|
| CUDA语言扩展 | C/C++(或Fortran、Python)加上GPU专用关键字 | __global__, __device__, __shared__ |
| CUDA工具链 | 编译器、调试器、性能分析工具 | nvcc, cuda-gdb, Nsight Systems |
| CUDA库 | 高性能数学与AI库 | cuBLAS(线代)、cuDNN(深度学习)、cuFFT(傅里叶变换) |
📚CUDA核心库分类
🔢 数学与线性代数库
- cuBLAS:矩阵运算(本文重点)
- cuSPARSE:稀疏矩阵计算
- cuFFT:快速傅里叶变换
- cuSOLVER:线性方程组求解
- cuRAND:随机数生成
🧠 深度学习与AI加速库
- cuDNN:神经网络加速
- TensorRT:推理优化
- NCCL:多GPU通信
🏗️CUDA vs CUDA-X:完整生态解析
🔗 CUDA 与 CUDA-X 的关系
NVIDIA GPU 的底层编程和运行平台,相当于整个生态系统的"地基"。提供编程模型、编译器(nvcc)、运行时和驱动程序。
基于 CUDA 面向各行业的优化组件与库集合,是完整的加速生态系统,覆盖 AI、HPC、数据科学、图形等领域。
"900 多个库"是指 CUDA-X 整个生态的总量(含所有子模块与工具集),而不是单个产品包里的数量。
CUDA 是底层编程和运行平台(地基);CUDA-X 是面向各行业的优化组件集合(上层建筑)。
CUDA
└── CUDA-X(900+库的完整生态)
├── CUDA-X AI(cuDNN, TensorRT, NCCL)
├── CUDA-X HPC(cuBLAS, cuFFT, cuSPARSE)
├── CUDA-X Data(RAPIDS:cuDF, cuML, cuGraph)
├── CUDA-X Vision(NPP, nvJPEG)
└── CUDA-X Graphics(OptiX, RTX SDKs)关系说明:
- CUDA是底层编程和运行平台(地基)
- CUDA-X是面向各行业的优化组件集合(上层建筑)
三、CUDA架构详解
🖥️CPU与GPU协同工作模型
在CUDA编程模型中,CPU(主机/Host)和GPU(设备/Device)各司其职,通过CUDA API进行通信与协作:
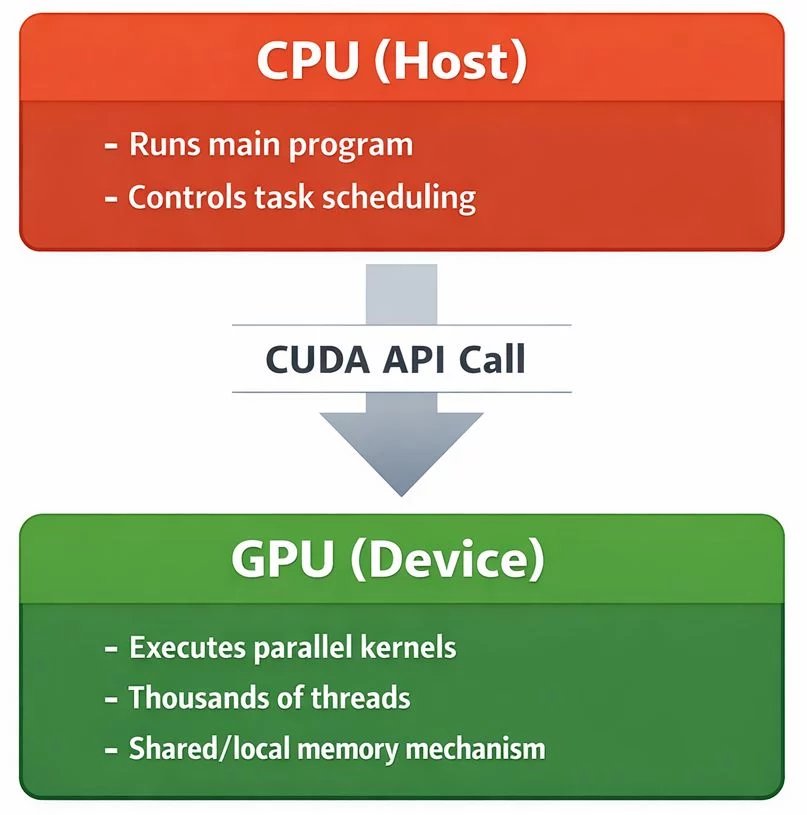
Host-Device 模型
CPU负责运行主程序和调度任务,GPU负责执行大规模并行计算。两者通过CUDA API调用进行数据传输和任务分发。
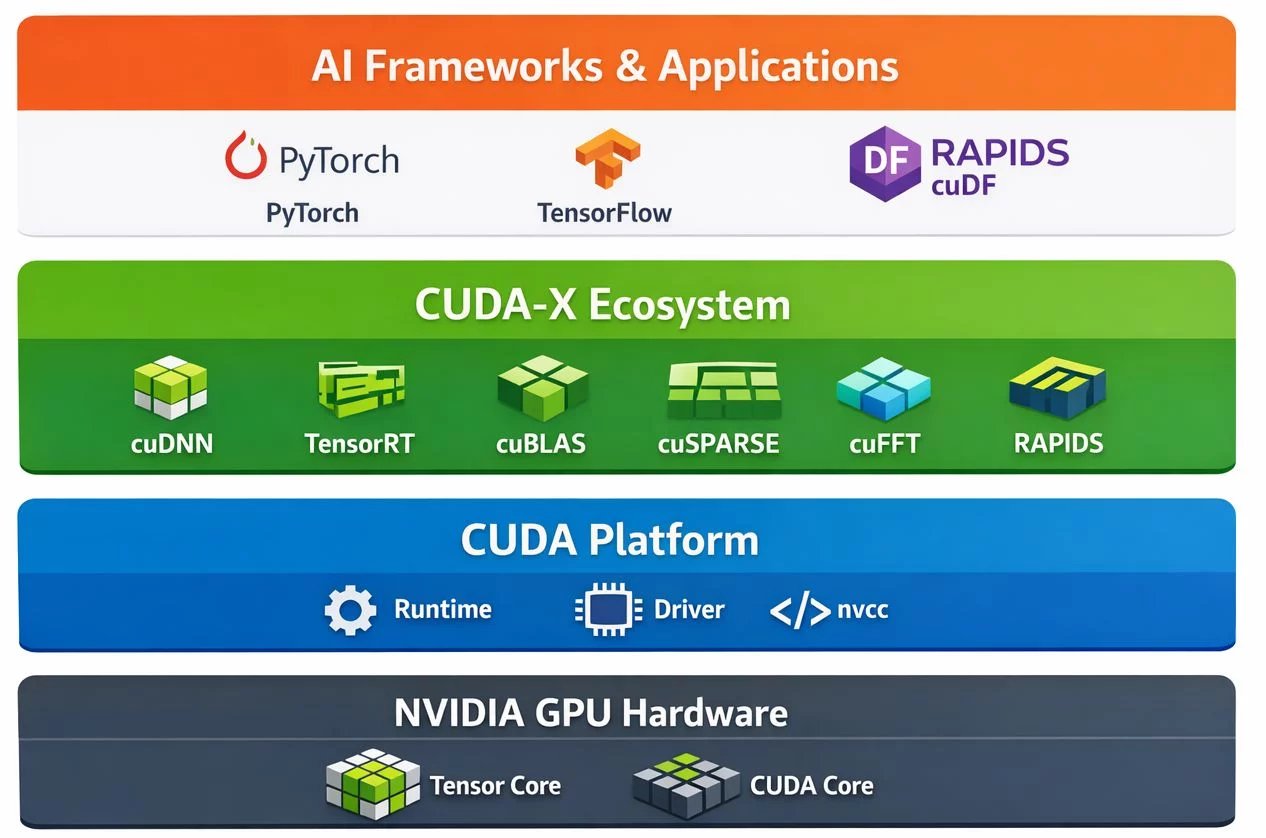
CUDA 完整技术栈
从底层的NVIDIA GPU硬件,到CUDA平台,再到CUDA-X生态系统,最终支撑上层的AI框架和应用程序。
📊技术栈层级详解
PyTorch · TensorFlow · RAPIDS cuDF
cuDNN · TensorRT · cuBLAS · cuSPARSE · cuFFT · RAPIDS
Runtime · Driver · nvcc Compiler
Tensor Core · CUDA Core
各层职责说明
| 层级 | 核心组件 | 职责 |
|---|---|---|
| 应用层 | PyTorch, TensorFlow, 自定义应用 | 面向开发者的高级API和框架 |
| CUDA-X生态 | cuDNN, TensorRT, cuBLAS等 | 领域优化库,提供开箱即用的高性能实现 |
| CUDA平台 | Runtime, Driver, nvcc | 编程模型、编译工具、运行时环境 |
| 硬件层 | Tensor Core, CUDA Core | 实际执行并行计算的物理单元 |
🔗PTX与CUDA的关系:编译工具链内部
在CUDA平台层内部,代码的编译和执行经历了多个阶段。理解PTX(Parallel Thread Execution)是掌握CUDA编译流程的关键。
编译流水线:从源码到机器码
开发者编写的 .cu 文件(含 __global__、__device__ 等关键字)
虚拟中间指令集(类似 LLVM IR / Java 字节码)
特定 GPU 架构的真实机器码(如 SM_86 对应 Ampere)
这一流程类比通用编程:
C/C++ 世界: 源码(.c) → 汇编(.s) → 机器码(.o)
Java 世界: 源码(.java) → 字节码(.class) → JIT 编译执行
CUDA 世界: 源码(.cu) → PTX(.ptx) → SASS(机器码)PTX 是什么?
PTX(Parallel Thread Execution)是 NVIDIA 定义的一种虚拟指令集架构(Virtual ISA)。它不是直接在硬件上运行的机器码,而是一层与具体 GPU 架构解耦的中间表示。
| 属性 | PTX | SASS |
|---|---|---|
| 性质 | 虚拟指令集(中间表示) | 真实机器码 |
| 硬件绑定 | 与 GPU 架构无关 | 绑定特定 GPU 架构(如 SM_86) |
| 可读性 | 文本格式,人类可读 | 二进制格式,需反汇编 |
| 生成工具 | nvcc -ptx |
ptxas 或驱动 JIT |
| 可移植性 | 跨 GPU 代际 | 仅限特定架构 |
PTX 的三大设计目的
1. 硬件无关性(前向兼容)
一份 PTX 代码可以在不同代的 GPU 上运行。旧版本编译生成的 PTX 可以由新驱动 JIT 编译到新架构上执行:
# 编译为 PTX(不绑定特定架构)
nvcc -ptx my_kernel.cu -o my_kernel.ptx
# 该 PTX 可以在 Ampere、Hopper、Blackwell 等架构上运行
# 驱动会在加载时自动 JIT 编译为对应的 SASS2. 离线编译 vs JIT 编译
方式一:离线编译(指定目标架构,生成 SASS)
nvcc -arch=sm_86 my_kernel.cu -o my_program
→ 直接嵌入 SM_86 的 SASS 机器码
→ 启动快,但只能在 SM_86 及兼容架构上运行
方式二:嵌入 PTX(运行时 JIT 编译)
nvcc -gencode arch=compute_86,code=compute_86 my_kernel.cu -o my_program
→ 嵌入 PTX 中间码
→ 首次运行时由驱动 JIT 编译为当前 GPU 的 SASS
→ 启动略慢,但兼容未来新架构
方式三:混合方式(推荐生产环境)
nvcc -gencode arch=compute_86,code=sm_86 \
-gencode arch=compute_86,code=compute_86 \
my_kernel.cu -o my_program
→ 同时嵌入 SASS(当前架构最优)和 PTX(未来兼容)3. 底层优化入口
开发者可以直接编写或内联 PTX 汇编,实现比 CUDA C 更细粒度的控制:
// 在 CUDA C 中内联 PTX 汇编
__device__ int my_optimized_op(int a, int b) {
int result;
asm volatile(
"add.s32 %0, %1, %2;" // PTX 加法指令
: "=r"(result) // 输出操作数
: "r"(a), "r"(b) // 输入操作数
);
return result;
}代码示例:CUDA C → PTX 对照
CUDA C 源码:
__global__ void add(float *a, float *b, float *c) {
int i = threadIdx.x;
c[i] = a[i] + b[i];
}对应 PTX(简化):
.visible .entry add(
.param .u64 a,
.param .u64 b,
.param .u64 c
) {
.reg .u64 %rd1, %rd2, %rd3, %rd4;
.reg .u32 %r1;
.reg .f32 %f1, %f2, %f3;
ld.param.u64 %rd1, [a]; // 加载参数(指针)
ld.param.u64 %rd2, [b];
ld.param.u64 %rd3, [c];
mov.u32 %r1, %tid.x; // 获取线程ID
// 计算地址偏移(i * 4 字节)
mul.wide.u32 %rd4, %r1, 4;
add.u64 %rd1, %rd1, %rd4;
add.u64 %rd2, %rd2, %rd4;
add.u64 %rd3, %rd3, %rd4;
ld.global.f32 %f1, [%rd1]; // 从全局内存加载 a[i]
ld.global.f32 %f2, [%rd2]; // 从全局内存加载 b[i]
add.f32 %f3, %f1, %f2; // 浮点加法
st.global.f32 [%rd3], %f3; // 存储结果到 c[i]
ret;
}关键理解:
- PTX 是 CUDA 编译工具链的中间层,让 CUDA 程序能够跨 GPU 代际运行
- 大多数开发者不需要直接接触 PTX,nvcc 会自动处理整个编译流程
- PTX 的前向兼容性是 CUDA 生态长期演进的重要保障——今天编译的程序能在未来的 GPU 上运行
- 性能敏感场景可通过内联 PTX 获得更底层的硬件控制(如 warp shuffle、特殊数学指令等)
⚡Host-Device 执行流程
典型CUDA程序执行步骤
- 数据准备(Host):CPU在主机内存中准备输入数据
- 内存分配(Device):使用
cudaMalloc在GPU显存中分配空间 - 数据传输(H→D):通过
cudaMemcpy将数据从CPU复制到GPU - 内核执行(Device):启动GPU Kernel执行并行计算
- 结果传输(D→H):将计算结果从GPU复制回CPU
- 资源释放:使用
cudaFree释放GPU内存
// CUDA程序执行流程示例
int main() {
// 1. Host: 准备数据
float *h_data = (float*)malloc(size);
// 2. Device: 分配GPU内存
float *d_data;
cudaMalloc(&d_data, size);
// 3. 数据传输: CPU → GPU
cudaMemcpy(d_data, h_data, size, cudaMemcpyHostToDevice);
// 4. Device: 执行并行计算
myKernel<<<blocks, threads>>>(d_data);
// 5. 数据传输: GPU → CPU
cudaMemcpy(h_data, d_data, size, cudaMemcpyDeviceToHost);
// 6. 释放资源
cudaFree(d_data);
free(h_data);
}关键理解:
- Host (CPU):运行主程序,控制任务调度,管理数据传输
- Device (GPU):执行并行Kernel,拥有成千上万个线程同时工作
- 瓶颈警示:PCIe数据传输带宽(~16 GB/s)远低于GPU显存带宽(~500 GB/s),需要尽量减少Host-Device数据传输
四、环境搭建与基础测试
⚙️安装步骤
1. 安装NVIDIA驱动
根据显卡型号下载对应驱动
2. 安装CUDA Toolkit
选择与驱动匹配的CUDA版本
安装后验证:
nvcc --version
# 输出示例:
# Cuda compilation tools, release 11.6, V11.6.1123. 安装Visual Studio(Windows)
- 安装VS2019(根据CUDA版本选择)
- 勾选"使用C++的桌面开发"
- 配置环境变量
✅环境验证
cd C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.6\extras\demo_suite
deviceQuery.exe测试输出示例
Device 0: "NVIDIA GeForce RTX 3050 Laptop GPU"
CUDA Capability: 8.6
Total Memory: 4096 MB
(16) Multiprocessors × (128) CUDA Cores/MP = 2048 CUDA Cores
GPU Max Clock: 1057 MHz
Memory Bus Width: 128-bit
Result = PASS ✓五、代码实战:矩阵加法 vs 矩阵乘法
➕矩阵加法(GPU实现)
核心代码结构
// CUDA Kernel:GPU上执行的函数
__global__ void matrixAdd(float *A, float *B, float *C, int width, int height) {
// 计算当前线程负责的元素位置
int col = blockIdx.x * blockDim.x + threadIdx.x;
int row = blockIdx.y * blockDim.y + threadIdx.y;
// 边界检查
if (row < height && col < width) {
int index = row * width + col;
C[index] = A[index] + B[index]; // 简单的加法运算
}
}
int main() {
// 1. 分配CPU和GPU内存
float *h_A, *h_B, *h_C; // host(CPU)
float *d_A, *d_B, *d_C; // device(GPU)
// 2. 数据传输:CPU → GPU
cudaMemcpy(d_A, h_A, SIZE, cudaMemcpyHostToDevice);
// 3. 配置线程布局并启动kernel
dim3 threadsPerBlock(16, 16); // 每个Block 256个线程
dim3 numBlocks((WIDTH+15)/16, (HEIGHT+15)/16);
matrixAdd<<<numBlocks, threadsPerBlock>>>(d_A, d_B, d_C, WIDTH, HEIGHT);
// 4. 数据传输:GPU → CPU
cudaMemcpy(h_C, d_C, SIZE, cudaMemcpyDeviceToHost);
}编译与运行
# 基本编译
nvcc matrix_add.cu -o matrix_add.exe
# 支持中文注释(UTF-8 with BOM)
nvcc matrix_add.cu -o matrix_add.exe -Xcompiler "/utf-8"
# 运行
matrix_add.exe📊性能对比:CPU vs GPU
🖥️ 测试环境
- GPU: NVIDIA GeForce RTX 3050 Laptop GPU
- CUDA Cores: 2048
- GPU Memory: 3770 MB
- CPU Threads: 16 (auto-detected)
CPU vs GPU 矩阵乘法基准测试
| 矩阵大小 | GPU (ms) | CPU (ms) | 加速比 | GPU GFLOPS |
|---|---|---|---|---|
| 1024×1024 | 66.21 | 355.78 | 5.4x | 32.43 |
| 2048×2048 | 64.29 | 3448.57 | 53.6x | 267.23 |
| 4096×4096 | 530.59 | 34297.56 | 64.6x | 259.03 |
| 8192×8192 | 5279.55 | (跳过) | - | 208.26 |
| 16384×16384 | 42100.96 | (跳过) | - | 208.93 |
测试说明:
- GPU时间 = 仅内核执行时间(不包括数据传输)
- CPU 使用16线程并行计算
- CPU测试 在 N > 4096 时跳过(耗时过长)
- GFLOPS = 每秒十亿次浮点运算
- 矩阵乘法运算量 = 2×N³ 次浮点运算
📈性能对比:加法 vs 乘法
矩阵加法测试结果
| 矩阵大小 | GPU总时间 | CPU总时间(8线程) | 胜者 | 备注 |
|---|---|---|---|---|
| 1024×1024 | 5.367 ms | 2.835 ms | CPU快1.9倍 | 数据传输占97% |
| 2048×2048 | 11.985 ms | 8.878 ms | CPU快1.3倍 | 传输瓶颈明显 |
矩阵乘法测试结果(Naive实现)
| 矩阵大小 | GPU时间 | CPU时间(16线程) | 加速比 | GPU GFLOPS |
|---|---|---|---|---|
| 1024×1024 | 66.21 ms | 355.78 ms | 5.4x | 32.43 |
| 2048×2048 | 64.29 ms | 3,448.57 ms | 53.6x | 267.23 |
| 4096×4096 | 530.59 ms | 34,297.56 ms | 64.6x | 259.03 |
| 8192×8192 | 5,279.55 ms | (太慢跳过) | - | 208.26 |
| 16384×16384 | 42,100.96 ms | (太慢跳过) | - | 208.93 |
关键发现:
矩阵加法:O(N²) 复杂度 → 内存带宽受限 → CPU胜
矩阵乘法:O(N³) 复杂度 → 计算密集 → GPU胜六、深度分析:为什么会有如此差异?
🔬GPU架构特点
RTX 3050 Laptop GPU规格
- CUDA Cores: 2048个
- 理论算力: ~5 TFLOPS(单精度浮点)
- 显存带宽: 128 GB/s(理论值)
- 实际PCIe带宽: 4-8 GB/s(瓶颈!)
❌矩阵加法失败原因
计算 vs 传输对比
1024×1024矩阵(4MB数据):
GPU计算时间:0.079 ms
└── 1,048,576个线程 ÷ 2048核心 = 512批次
└── 每批次只需微秒级
数据传输时间:5.279 ms
├── CPU→GPU:4MB 数据 × 2 = 8MB
└── GPU→CPU:4MB 结果
└── PCIe带宽只有4 GB/s(远低于128 GB/s显存带宽)问题本质:
GPU就像一个超级计算器,但放在很远的地方
取数据 → 算一下(0.079ms) → 送回结果(5.279ms)
↑快 ↑慢67倍!
CPU就像手边的普通计算器
直接算(2.835ms),无需搬运✅矩阵乘法成功原因
计算密度对比
矩阵加法:C[i][j] = A[i][j] + B[i][j]
└── 读2次,算1次,写1次
└── 计算/访存比 = 1:3(访存为主)
矩阵乘法:C[i][j] = Σ(A[i][k] × B[k][j])
└── 对于N×N矩阵,每个元素需要N次乘加
└── 计算/访存比 = N:2(计算为主)
└── N=1024时,计算量是访存的512倍!效率提升原理
假设1024×1024矩阵乘法:
总运算次数 = 2 × 1024³ ≈ 21.5亿次浮点运算
传输数据量 = 3 × 4MB = 12MB
GPU每次传输12MB,可以做21.5亿次计算
这时传输开销被计算时间"稀释"了七、优化策略:从270 GFLOPS到4300 GFLOPS
🚀三种实现方式对比
| 实现方式 | GFLOPS | 理论峰值占比 | 关键技术 |
|---|---|---|---|
| Naive(朴素) | 270 | 5.4% | 直接全局内存访问 |
| Tiled(分块) | 400 | 8% | 共享内存优化 |
| cuBLAS(官方库) | 4300 | 86% | 寄存器分块+循环展开+预取 |
🎨性能可视化
💻Naive实现(基础版)
__global__ void matrixMulNaive(float *A, float *B, float *C, int N) {
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
if (row < N && col < N) {
float sum = 0.0f;
for (int k = 0; k < N; k++) {
sum += A[row * N + k] * B[k * N + col];
// ↑每次都从全局显存读取(慢!400周期延迟)
}
C[row * N + col] = sum;
}
}性能瓶颈
- 每个线程读取2N个元素(A的一行 + B的一列)
- 全局显存延迟 ~400 周期
- 1024×1024矩阵:每个线程等待 ~800,000 周期!
⚡Tiled实现(共享内存优化)
#define TILE_SIZE 32
__global__ void matrixMulTiled(float *A, float *B, float *C, int N) {
__shared__ float As[TILE_SIZE][TILE_SIZE]; // 共享内存
__shared__ float Bs[TILE_SIZE][TILE_SIZE];
int row = blockIdx.y * TILE_SIZE + threadIdx.y;
int col = blockIdx.x * TILE_SIZE + threadIdx.x;
float sum = 0.0f;
// 分块计算
for (int t = 0; t < (N + TILE_SIZE - 1) / TILE_SIZE; t++) {
// 协作加载Tile到共享内存
if (row < N && t * TILE_SIZE + threadIdx.x < N)
As[threadIdx.y][threadIdx.x] = A[row * N + t * TILE_SIZE + threadIdx.x];
else
As[threadIdx.y][threadIdx.x] = 0.0f;
if (col < N && t * TILE_SIZE + threadIdx.y < N)
Bs[threadIdx.y][threadIdx.x] = B[(t * TILE_SIZE + threadIdx.y) * N + col];
else
Bs[threadIdx.y][threadIdx.x] = 0.0f;
__syncthreads(); // 等待所有线程加载完成
// 使用共享内存计算(快!~20周期延迟)
for (int k = 0; k < TILE_SIZE; k++)
sum += As[threadIdx.y][k] * Bs[k][threadIdx.x];
__syncthreads();
}
if (row < N && col < N)
C[row * N + col] = sum;
}优化效果
内存访问速度对比:
寄存器: ~0 周期
共享内存: ~20 周期(比全局快20倍!)
L1/L2缓存: ~30-200 周期
全局显存: ~400 周期
Tiled方法:
- 将32×32的块加载到共享内存
- Block内256个线程共享这些数据
- 减少全局内存访问 32倍
- 性能提升:270 → 400 GFLOPS(1.5倍)🏆cuBLAS实现(专业级)
#include <cublas_v2.h>
void matrixMulCuBLAS(float *A, float *B, float *C, int N) {
cublasHandle_t handle;
cublasCreate(&handle);
const float alpha = 1.0f;
const float beta = 0.0f;
// C = alpha * A × B + beta * C
cublasSgemm(handle, CUBLAS_OP_N, CUBLAS_OP_N,
N, N, N,
&alpha,
A, N,
B, N,
&beta,
C, N);
cublasDestroy(handle);
}cuBLAS的三大杀器
1️⃣ 寄存器分块(Register Blocking)
// 普通方式:每次从共享内存读
for (int k = 0; k < N; k++)
sum += A[i][k] * B[k][j]; // 每次20周期
// 寄存器分块:先加载到寄存器
float a0=A[i][0], a1=A[i][1], a2=A[i][2], a3=A[i][3];
float b0=B[0][j], b1=B[1][j], b2=B[2][j], b3=B[3][j];
sum = a0*b0 + a1*b1 + a2*b2 + a3*b3; // 寄存器运算:~0周期2️⃣ 循环展开(Loop Unrolling)
// 展开前:有跳转开销
for (int i = 0; i < 8; i++)
sum += a[i] * b[i];
// 展开后:减少跳转,增加并行
sum += a[0]*b[0] + a[1]*b[1] + a[2]*b[2] + a[3]*b[3]
+ a[4]*b[4] + a[5]*b[5] + a[6]*b[6] + a[7]*b[7];3️⃣ 内存预取(Prefetching)
// 软件流水线
float next_tile = load_next_tile();
for (int t = 0; t < num_tiles; t++) {
float current = next_tile;
next_tile = load_next_tile(); // 异步加载
compute(current); // 同时计算
}
// 内存延迟被计算时间"隐藏"编译cuBLAS程序
nvcc matrix_mul_opt.cu -o matrix_mul_opt.exe \
-L"%CUDA_PATH%\lib\x64" -lcublas八、CUDA Core vs Tensor Core 完整对比
为了全面比较不同实现的性能差异,我们测试了5种矩阵乘法实现:Naive、Tiled、cuBLAS CUDA Core、cuBLAS TF32 Tensor Core、cuBLAS FP16 Tensor Core。
📊 测试环境
- GPU: NVIDIA GeForce RTX 3050 Laptop GPU
- CUDA Cores: 2048
- Tensor Cores: 64 (estimated)
- GPU Memory: 3770 MB
- Compute Capability: 8.6
🔧 数学模式说明
- CUDA Core: CUBLAS_DEFAULT_MATH (FP32 input, CUDA Cores only)
- TensorCore TF32: CUBLAS_TF32_TENSOR_OP_MATH (FP32 input, TF32 compute)
- TensorCore FP16: cublasGemmEx (FP16 input, FP32 output, max throughput)
完整测试结果
| Size | Naive (ms) | Tiled (ms) | CUDA Core (ms) | TC TF32 (ms) | TC FP16 (ms) | Speedup | FP16 GFLOPS |
|---|---|---|---|---|---|---|---|
| 1024 | 44.48 | 6.78 | 50.20 | 1.45 | 72.03 | 0.70x | 29.8 |
| 2048 | 64.26 | 53.94 | 6.28 | 4.12 | 2.14 | 2.94x | 8,046.6 |
| 4096 | 521.81 | 303.46 | 34.64 | 33.63 | 12.67 | 2.73x | 10,844.1 |
| 8192 | skipped | skipped | 331.68 | 191.73 | 99.36 | 3.34x | 11,066.1 |
| 16384 | skipped | skipped | 4,874.63 | 1,532.74 | 788.90 | 6.18x | 11,149.8 |
关键观察
- 小矩阵(1024):Tensor Core FP16反而更慢,因为启动开销大于计算收益
- 中等矩阵(2048-4096):Tensor Core开始展现优势,TF32和FP16均显著加速
- 大矩阵(8192+):Tensor Core FP16达到6x加速,GFLOPS稳定在11,000+
- Tiled优化:在小矩阵上比Naive快6-10倍,但在中等矩阵上优势减小
内存占用参考
| 矩阵大小 | FP32 (每矩阵) | FP16 (每矩阵) |
|---|---|---|
| 1024 × 1024 | 4 MB | 2 MB |
| 2048 × 2048 | 16 MB | 8 MB |
| 4096 × 4096 | 64 MB | 32 MB |
| 8192 × 8192 | 256 MB | 128 MB |
| 16384 × 16384 | 1024 MB | 512 MB |
完整测试代码
#include <stdio.h>
#include <stdlib.h>
#include <cuda_runtime.h>
#include <cuda_fp16.h>
#include <cublas_v2.h>
// ============== Configuration ==============
int SIZES[] = {1024, 2048, 4096, 8192, 16384};
#define NUM_SIZES (sizeof(SIZES) / sizeof(SIZES[0]))
#define TILE_SIZE 32
// ============== 1. Naive Implementation (CUDA Core) ==============
__global__ void matrixMulNaive(float *A, float *B, float *C, int N) {
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
if (row < N && col < N) {
float sum = 0.0f;
for (int k = 0; k < N; k++) {
sum += A[row * N + k] * B[k * N + col];
}
C[row * N + col] = sum;
}
}
// ============== 2. Tiled Implementation (Shared Memory, CUDA Core) ==============
__global__ void matrixMulTiled(float *A, float *B, float *C, int N) {
__shared__ float tileA[TILE_SIZE][TILE_SIZE];
__shared__ float tileB[TILE_SIZE][TILE_SIZE];
int row = blockIdx.y * TILE_SIZE + threadIdx.y;
int col = blockIdx.x * TILE_SIZE + threadIdx.x;
float sum = 0.0f;
for (int t = 0; t < (N + TILE_SIZE - 1) / TILE_SIZE; t++) {
if (row < N && t * TILE_SIZE + threadIdx.x < N)
tileA[threadIdx.y][threadIdx.x] = A[row * N + t * TILE_SIZE + threadIdx.x];
else
tileA[threadIdx.y][threadIdx.x] = 0.0f;
if (col < N && t * TILE_SIZE + threadIdx.y < N)
tileB[threadIdx.y][threadIdx.x] = B[(t * TILE_SIZE + threadIdx.y) * N + col];
else
tileB[threadIdx.y][threadIdx.x] = 0.0f;
__syncthreads();
for (int k = 0; k < TILE_SIZE; k++) {
sum += tileA[threadIdx.y][k] * tileB[k][threadIdx.x];
}
__syncthreads();
}
if (row < N && col < N) {
C[row * N + col] = sum;
}
}
// ============== Benchmark Functions ==============
float benchmarkNaive(int N, bool skip_large) {
if (skip_large && N > 4096) return -1;
size_t size = N * N * sizeof(float);
float *d_A, *d_B, *d_C;
if (cudaMalloc(&d_A, size) != cudaSuccess) return -1;
if (cudaMalloc(&d_B, size) != cudaSuccess) { cudaFree(d_A); return -1; }
if (cudaMalloc(&d_C, size) != cudaSuccess) { cudaFree(d_A); cudaFree(d_B); return -1; }
cudaMemset(d_A, 0, size);
cudaMemset(d_B, 0, size);
dim3 threadsPerBlock(16, 16);
dim3 numBlocks((N + 15) / 16, (N + 15) / 16);
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start);
matrixMulNaive<<<numBlocks, threadsPerBlock>>>(d_A, d_B, d_C, N);
cudaEventRecord(stop);
cudaEventSynchronize(stop);
float ms = 0;
cudaEventElapsedTime(&ms, start, stop);
cudaEventDestroy(start);
cudaEventDestroy(stop);
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
return ms;
}
float benchmarkTiled(int N, bool skip_large) {
if (skip_large && N > 4096) return -1;
size_t size = N * N * sizeof(float);
float *d_A, *d_B, *d_C;
if (cudaMalloc(&d_A, size) != cudaSuccess) return -1;
if (cudaMalloc(&d_B, size) != cudaSuccess) { cudaFree(d_A); return -1; }
if (cudaMalloc(&d_C, size) != cudaSuccess) { cudaFree(d_A); cudaFree(d_B); return -1; }
cudaMemset(d_A, 0, size);
cudaMemset(d_B, 0, size);
dim3 threadsPerBlock(TILE_SIZE, TILE_SIZE);
dim3 numBlocks((N + TILE_SIZE - 1) / TILE_SIZE, (N + TILE_SIZE - 1) / TILE_SIZE);
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start);
matrixMulTiled<<<numBlocks, threadsPerBlock>>>(d_A, d_B, d_C, N);
cudaEventRecord(stop);
cudaEventSynchronize(stop);
float ms = 0;
cudaEventElapsedTime(&ms, start, stop);
cudaEventDestroy(start);
cudaEventDestroy(stop);
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
return ms;
}
float benchmarkCuBLAS_FP32(int N, cublasHandle_t handle) {
size_t size = N * N * sizeof(float);
float *d_A, *d_B, *d_C;
if (cudaMalloc(&d_A, size) != cudaSuccess) return -1;
if (cudaMalloc(&d_B, size) != cudaSuccess) { cudaFree(d_A); return -1; }
if (cudaMalloc(&d_C, size) != cudaSuccess) { cudaFree(d_A); cudaFree(d_B); return -1; }
cudaMemset(d_A, 0, size);
cudaMemset(d_B, 0, size);
const float alpha = 1.0f;
const float beta = 0.0f;
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start);
cublasSgemm(handle, CUBLAS_OP_N, CUBLAS_OP_N, N, N, N,
&alpha, d_B, N, d_A, N, &beta, d_C, N);
cudaEventRecord(stop);
cudaEventSynchronize(stop);
float ms = 0;
cudaEventElapsedTime(&ms, start, stop);
cudaEventDestroy(start);
cudaEventDestroy(stop);
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
return ms;
}
float benchmarkCuBLAS_TF32(int N, cublasHandle_t handle) {
size_t size = N * N * sizeof(float);
float *d_A, *d_B, *d_C;
if (cudaMalloc(&d_A, size) != cudaSuccess) return -1;
if (cudaMalloc(&d_B, size) != cudaSuccess) { cudaFree(d_A); return -1; }
if (cudaMalloc(&d_C, size) != cudaSuccess) { cudaFree(d_A); cudaFree(d_B); return -1; }
cudaMemset(d_A, 0, size);
cudaMemset(d_B, 0, size);
const float alpha = 1.0f;
const float beta = 0.0f;
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start);
cublasSgemm(handle, CUBLAS_OP_N, CUBLAS_OP_N, N, N, N,
&alpha, d_B, N, d_A, N, &beta, d_C, N);
cudaEventRecord(stop);
cudaEventSynchronize(stop);
float ms = 0;
cudaEventElapsedTime(&ms, start, stop);
cudaEventDestroy(start);
cudaEventDestroy(stop);
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
return ms;
}
float benchmarkCuBLAS_FP16(int N, cublasHandle_t handle) {
size_t size_fp16 = N * N * sizeof(half);
size_t size_fp32 = N * N * sizeof(float);
half *d_A, *d_B;
float *d_C;
if (cudaMalloc(&d_A, size_fp16) != cudaSuccess) return -1;
if (cudaMalloc(&d_B, size_fp16) != cudaSuccess) { cudaFree(d_A); return -1; }
if (cudaMalloc(&d_C, size_fp32) != cudaSuccess) { cudaFree(d_A); cudaFree(d_B); return -1; }
cudaMemset(d_A, 0, size_fp16);
cudaMemset(d_B, 0, size_fp16);
const float alpha = 1.0f;
const float beta = 0.0f;
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start);
cublasGemmEx(handle, CUBLAS_OP_N, CUBLAS_OP_N, N, N, N,
&alpha, d_B, CUDA_R_16F, N, d_A, CUDA_R_16F, N,
&beta, d_C, CUDA_R_32F, N,
CUBLAS_COMPUTE_32F, CUBLAS_GEMM_DEFAULT_TENSOR_OP);
cudaEventRecord(stop);
cudaEventSynchronize(stop);
float ms = 0;
cudaEventElapsedTime(&ms, start, stop);
cudaEventDestroy(start);
cudaEventDestroy(stop);
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
return ms;
}
// ============== Main ==============
int main() {
printf("Matrix Multiplication: CUDA Core vs Tensor Core Comparison\n\n");
cudaDeviceProp prop;
cudaGetDeviceProperties(&prop, 0);
printf("GPU: %s\n", prop.name);
printf("CUDA Cores: %d\n", prop.multiProcessorCount * 128);
printf("Tensor Cores: %d (estimated)\n", prop.multiProcessorCount * 4);
printf("GPU Memory: %.0f MB\n", prop.totalGlobalMem / (1024.0 * 1024.0));
printf("Compute Capability: %d.%d\n\n", prop.major, prop.minor);
cublasHandle_t handle_cuda_core;
cublasHandle_t handle_tensor_tf32;
cublasHandle_t handle_tensor_fp16;
cublasCreate(&handle_cuda_core);
cublasCreate(&handle_tensor_tf32);
cublasCreate(&handle_tensor_fp16);
cublasSetMathMode(handle_cuda_core, CUBLAS_DEFAULT_MATH);
cublasSetMathMode(handle_tensor_tf32, CUBLAS_TF32_TENSOR_OP_MATH);
cublasSetMathMode(handle_tensor_fp16, CUBLAS_DEFAULT_MATH);
printf("| Size | Naive | Tiled | CUDA Core| TC TF32 | TC FP16 | Speedup | GFLOPS |\n");
printf("|-------|----------|----------|----------|----------|----------|----------|----------|\n");
for (int i = 0; i < NUM_SIZES; i++) {
int N = SIZES[i];
float time_naive = benchmarkNaive(N, true);
float time_tiled = benchmarkTiled(N, true);
float time_cublas_cuda = benchmarkCuBLAS_FP32(N, handle_cuda_core);
float time_cublas_tf32 = benchmarkCuBLAS_TF32(N, handle_tensor_tf32);
float time_cublas_fp16 = benchmarkCuBLAS_FP16(N, handle_tensor_fp16);
if (time_cublas_fp16 < 0) {
printf("| %5d | GPU memory allocation failed\n", N);
continue;
}
double ops = 2.0 * N * N * N;
double gflops_fp16 = ops / (time_cublas_fp16 * 1e6);
float speedup_fp16 = (time_cublas_cuda > 0) ? time_cublas_cuda / time_cublas_fp16 : 0;
if (time_naive > 0 && time_tiled > 0) {
printf("| %5d | %8.2f | %8.2f | %8.2f | %8.2f | %8.2f | %7.2fx | %9.1f |\n",
N, time_naive, time_tiled, time_cublas_cuda, time_cublas_tf32,
time_cublas_fp16, speedup_fp16, gflops_fp16);
} else {
printf("| %5d | skipped | skipped | %8.2f | %8.2f | %8.2f | %7.2fx | %9.1f |\n",
N, time_cublas_cuda, time_cublas_tf32,
time_cublas_fp16, speedup_fp16, gflops_fp16);
}
}
cublasDestroy(handle_cuda_core);
cublasDestroy(handle_tensor_tf32);
cublasDestroy(handle_tensor_fp16);
return 0;
}编译命令
# Linux
nvcc tensor_core_benchmark.cu -o tensor_core_benchmark -lcublas
# Windows
nvcc tensor_core_benchmark.cu -o tensor_core_benchmark.exe -L"%CUDA_PATH%\lib\x64" -lcublas📋 图例说明
- Naive: 基础CUDA kernel,每个线程计算一个元素
- Tiled: 使用共享内存优化的CUDA kernel,tile size = 32×32
- CUDA Core: cuBLAS FP32 with CUBLAS_DEFAULT_MATH(仅CUDA Cores)
- TC TF32: cuBLAS FP32 with CUBLAS_TF32_TENSOR_OP_MATH(Tensor Cores)
- TC FP16: cuBLAS FP16 input with cublasGemmEx(Tensor Cores,最高吞吐)
- Speedup: CUDA Core time / TC FP16 time
- GFLOPS: 基于TC FP16时间计算的性能
结论
Tensor Core的真正价值在于大规模矩阵运算。对于16384×16384的矩阵,Tensor Core FP16相比CUDA Core实现了6.18倍加速,达到了11,149 GFLOPS的吞吐量。这正是深度学习训练能够高效利用GPU的关键原因。
🤔 为什么没有达到理论峰值?
RTX 3050 Laptop GPU 的 Tensor Core FP16 理论峰值约为 73.5 TFLOPS,而我们只测得 11.1 TFLOPS(约15%利用率)。主要原因:
| 瓶颈因素 | 影响 | 说明 |
|---|---|---|
| 内存带宽限制 | 主要瓶颈 | RTX 3050 仅 128-bit 总线,带宽约 192 GB/s,无法喂饱 Tensor Core |
| 笔记本功耗墙 | 显著影响 | Laptop GPU 功耗限制在 35-80W,频率和性能受限 |
| 单次 GEMM 调用 | 中等影响 | 实际训练中会批量处理多个矩阵,提高 GPU 利用率 |
| 矩阵对齐/填充 | 轻微影响 | Tensor Core 要求特定对齐(如 8/16 倍数),非最优尺寸有额外开销 |
理论 vs 实际性能对比:
┌─────────────────────────────────────────────────────┐
│ Tensor Core FP16 理论峰值: 73.5 TFLOPS (100%) │
│ 内存带宽理论上限: ~24 TFLOPS (33%) │ ← 带宽瓶颈
│ 实测性能: ~11 TFLOPS (15%) │
└─────────────────────────────────────────────────────┘
计算瓶颈分析(16384×16384 矩阵):
- 运算量: 2×16384³ = 8.8 万亿次浮点运算
- 数据量: 3×16384²×2 = 1.5 GB (FP16)
- 计算强度: 8.8T / 1.5G ≈ 5800 FLOP/Byte
- 理论需要带宽: 73.5T / 5800 ≈ 12.7 GB/s(远低于192 GB/s)
结论:大矩阵理论上不应受带宽限制,
实际瓶颈在于笔记本功耗限制和 GPU 调度效率。九、实战建议与最佳实践
🤔什么时候用GPU?
| 任务类型 | 建议 | 原因 |
|---|---|---|
| 简单元素操作(加法、赋值) | ❌ 不建议 | 传输开销 > 计算收益 |
| 矩阵乘法 | ✅ 强烈推荐 | 计算密集,GPU快50-70倍 |
| 深度学习训练 | ✅ 必须 | 大量矩阵运算 + 数据复用 |
| 图像/视频处理 | ✅ 推荐 | 天然并行 + 数据量大 |
| 科学计算(FFT、求解器) | ✅ 推荐 | 算法复杂度高 |
📋优化检查清单
✅ 基础优化
- ☑ 使用官方库(cuBLAS、cuDNN等)而非手写kernel
- ☑ 减少CPU-GPU数据传输次数
- ☑ 使用Pinned Memory加速传输
- ☑ 批量处理数据而非逐个处理
✅ 进阶优化
- ☑ 使用共享内存减少全局内存访问
- ☑ 优化线程块大小(通常16×16或32×32)
- ☑ 避免Bank Conflict(共享内存访问冲突)
- ☑ 使用CUDA Streams实现并发
✅ 性能分析
- ☑ 使用
nvprof或Nsight Compute分析性能 - ☑ 检查GPU占用率(应 >80%)
- ☑ 检查内存带宽利用率
- ☑ 识别性能瓶颈(计算 vs 内存 vs 传输)
⚠️常见陷阱
// ❌ 错误:频繁小数据传输
for (int i = 0; i < 1000; i++) {
cudaMemcpy(d_data, &h_data[i], sizeof(float), cudaMemcpyHostToDevice);
kernel<<<1, 256>>>(d_data);
cudaMemcpy(&h_result[i], d_data, sizeof(float), cudaMemcpyDeviceToHost);
}
// ✅ 正确:批量传输
cudaMemcpy(d_data, h_data, 1000 * sizeof(float), cudaMemcpyHostToDevice);
kernel<<<4, 256>>>(d_data); // 一次性处理
cudaMemcpy(h_result, d_data, 1000 * sizeof(float), cudaMemcpyDeviceToHost);十、总结
🎯核心要点
1. CUDA = GPU通用计算平台
不只是库,是完整生态(语言扩展 + 工具链 + 900+库)
让GPU从图形加速器变成通用超级计算器
2. 性能的秘密在于计算密度
矩阵加法:1次计算/元素 → CPU胜(传输开销太大)
矩阵乘法:N次计算/元素 → GPU胜(计算掩盖传输)3. 优化有层次
Naive实现: 270 GFLOPS (5%理论峰值)
Tiled优化: 400 GFLOPS (8%理论峰值)
cuBLAS专业库: 4300 GFLOPS (86%理论峰值)
结论:学习原理用Naive/Tiled,生产环境用cuBLAS4. GPU的真正优势
- 简单操作(O(N)、O(N²)):可能不如CPU
- 复杂计算(O(N³)及以上):50-100倍加速
- 数据已在GPU:避免传输,发挥全部威力
🗺️学习路径建议
初学者
- 理解GPU架构(SM、线程、内存层次)
- 手写简单kernel(向量加法、矩阵加法)
- 学习优化(共享内存、寄存器)
- 使用官方库(cuBLAS、cuDNN)
进阶者
- 性能分析(nvprof、Nsight)
- 高级优化(Warp、Bank Conflict)
- 多GPU编程(NCCL)
- 深入特定领域(深度学习、科学计算)
💬实战金句
"GPU不是万能的,但在它擅长的领域,它是无敌的"
"不要重复造轮子——cuBLAS这样的库是几十个PhD花了十年优化的结果"
"数据传输是GPU编程的第一大敌,减少传输比优化kernel更重要"
"理论峰值只是数字,实际性能取决于你对硬件的理解"
附录:快速参考
📝常用CUDA命令
# 查看CUDA版本
nvcc --version
# 查看GPU信息
nvidia-smi
# 编译CUDA程序
nvcc program.cu -o program
# 编译并链接cuBLAS
nvcc program.cu -o program -lcublas
# 性能分析
nvprof ./program🔧关键API速查
// 内存管理
cudaMalloc(&d_ptr, size); // 分配GPU内存
cudaMemcpy(dst, src, size, type); // 数据传输
cudaFree(d_ptr); // 释放GPU内存
// Kernel启动
kernel<<<numBlocks, threadsPerBlock>>>(args);
// 同步
cudaDeviceSynchronize(); // 等待GPU完成
// 事件计时
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventRecord(start);
// ... kernel ...
cudaEventRecord(stop);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&ms, start, stop);⚡性能调优表
| 瓶颈类型 | 症状 | 解决方案 |
|---|---|---|
| 内存带宽 | GPU利用率低,内存吞吐高 | 使用共享内存、合并访问 |
| 计算能力 | GPU利用率高,内存吞吐低 | 增加并行度、优化算法 |
| 传输瓶颈 | kernel时间 << 总时间 | 减少传输、使用Pinned Memory |
| 占用率低 | SM利用率 < 50% | 调整Block大小、增加并发 |